If I’m being honest….
I’m always surprised when things work, not when they break. This may sound a bit pessimistic, and it probably is, but the reality is that the software we build is incredibly complex. Consider even the simplest Python program a new programmer might write:
print("Hello, world!\n")To the new programmer there is only one command, print and then some data
is output to the screen. Little do they know that behind that print statement
is just over 470 thousand lines of code that compose the Python interpreter.
Add to that the amount of code required to make the operating system itself even able to execute Python in the first place and it adds up to a lot of
components working in just the right way.
We are not bound by your silly laws!
Software is not limited by what most would consider the “normal” laws of the universe; we are not bound by gravity and the physical properties of materials because, hey, guess what? It turns out that two things actually can exist in the same place at the same time! Courtesy of parallelism techniques like threads and multiple processors, it’s very easy to end up tripping over ourselves. It still amazes me that we are still able to build anything we can dream of, and have it work “most of the time” by anyone’s standards.
As a result, complexity is often an an unintended side effect; behind even the simplest of programs is a mind-boggling amount of plumbing. It’s very easy to see how we, as developers, are often oblivious to a system’s complexity until it stops working and we have to figure out what the problem is.
… How does this thing even work?
It is our job to learn how to understand, identify, and (most importantly) manage that complexity. But, let’s take a look at some of the reasons behind why our systems are complex:
- Dependencies make life easy but complicated.
- You can’t actually see what is happening inside the system.
- The systems themselves are composed of many moving parts.
- We don’t necessarily see how complex our code truly is.
Once we understand where the source(s) of the complexities are, we can begin to identify and contain them. Processes such as monitoring, graphing, and writing tests ensure things work in spite of all these challenges.
Dependencies multiply like bunnies
As an illustrated example, I figured I would generate the dependency graph of a
widely used JavaScript web framework, Express. To do so, I installed a handy tool
called npm-remote-ls that would fetch this data for me. This tool alone required
112 packages from 99 contributors in order to do its job.
As you can see, the dependency graph for Express is very large, in fact, there
are 236 packages that the express package depends on, between direct and
indirect dependencies. A simple hello-world type Express.JS project will require
this many NPM packages just to get started!
Now, most of this is due to the fact that leveraging libraries allows us to cut down
on the amount of code we have to write; there’s not much point in everybody
needing to re-implement something like serve-static. By being able to re-use code
that others have written we are able to build new applications and libraries
more rapidly than if we had to implement everything. The cost, though, is that
these immediate dependencies often have dependencies of their own in turn.
Just like most anything, dependencies represent a double-edged sword; they serve a very useful purpose in helping us be productive developers. The important part is to know what you’re getting yourself into when you decide to take them on.
Distributed computing? More like chasing geese
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable. — Leslie Lamport
At one point in my tenure at Amazon, I worked on the internal deployment system called Apollo. Apollo is an amazing piece of machinery but that’s beyond the scope of this bit. What is relevant, however, is an outage that was caused by a piece of hardware nobody on our team knew even existed. Without going into too many details, let’s just say that Apollo was composed of a lot of services; thirty or more to be exact, some written in C++, some in Java, parts of it in Perl. Put mildly, it was a very challenging system to operate after over a decade of existence.
At the time in questio, Apollo had stopped doing deployments. Basically, it had come to a screeching halt. No new deployments were happening, current deployments were stalling out, it was throwing a “a no-way, no-how, not-gonna-do-it” temper tantrum. Restarting services didn’t fix it, everything seemed like it should be working but everything was effectively deadlocked. After a few stressful hours of “turning it off and back on again” along with log-snooping and trying lots of fixes, it became clear that the database backend (an enormous Oracle system) would accept queries but then, in some cases, block indefinitely on answering them.
The fact that the database had stopped functioning was not entirely obvious because the database appeared to be up - connections were happening, we weren’t overloading the connection pools, a number of queries were being answered eventually. Since the database was not under the control of the team, we had to call in the DBA folks to help fix it; they ended up manually failing over to the secondary database, folks restarted services and babysat the system for a few hours to make sure things were back to normal.
But, wait, what happened?
Well, nobody quite knew what had happened - the DBAs had no root cause as to what happened,
and folks on the team weren’t sure either. I asked one of the DBA folks if
I could look at the system logs from the failed database to see if I could figure out what went
wrong so we could avoid it in the future. In doing so I discovered something
interesting – the logs in /var/log (for a completely different service) looked something like this:
May 30 00:00:21 wintermute systemd[1]: Starting Rotate log files...
May 30 00:00:21 wintermute systemd[1]: Starting Daily man-db regeneration...
May 30 00:00:21 wintermute systemd[1]: man-And that was it, the end of the file looked like it just disappeared into the void. So, I thought about it and came to the conclusion that, for some reason, the system simply stopped writing data to disk. Everything else was responding, the network daemons, etc. were all happy.
… in which a RAID controller is the culprit
On a hunch, I asked my manager if the database servers hard hardware RAID controllers in them; he wasn’t sure but asked why. My answer to him was ‘I think maybe there’s a RAID controller in the machine and it silently stopped writing to disk but didn’t cause the kernel to crash’ – to which he thought I was crazy but we went ahead and asked the DBAs – sure enough there was, indeed, a RAID controller that they didn’t think twice about. After I told them my theory, they tested the device; they discovered that the RAID controller had, in fact, failed silently causing the database to continue thinking it could serve clients while it waited on some I/O to happen.
“I’m simultaneously annoyed and impressed that you were right.” – my manager
The moral of the story here is that our universe is incredibly complicated. Complicated in ways we wouldn’t ever expect and certainly in ways that no one individual can keep everything in their head.
◊(Perception ≠ Reality)
Sometimes code that we perceive to be simple is, in reality, a complex mechanism hiding behind an illusion of simplicity. As developers, we are often encouraged to hide things behind façades that can make it a challenge to fully understand what’s happening under the hood. Much in the way a car seems simple to its operator – I press the gas pedal, it goes, I press the brake, it stops – the underlying mechanisms, the internal combustion engine or advanced regenerative braking system, are much more complex than the interface we are presented with - two pedals.
Consider the following, seemingly simple, Python code:
import sys
from ecommerce.taxes import TaxCalculator
from ecommerce.shipping import calculate_shipping_price
from ecommerce.users import get_customer_shipping_info
def calculate_shipping(cart):
shipping_info = get_customer_shipping_info(cart.customer)
total_shipping = calculate_shipping_price(cart, shipping_info)
shipping_tax = calculate_tax(total_shipping, shipping_info)
return total_shipping + shipping_tax
def calculate_tax(amount, shipping_info):
t = TaxCalculator(amount, shipping_info.taxable_location)
return tWith a cursory glance, we can tell that we are calculating shipping and tax
costs and that the behavior of this code is dependent on the properties of our
shopping cart (items in the cart, customer who owns the cart, location of that
customer) and that if any of those properties change the result of calculate shipping would likely be different (i.e a different state for billing, adding
things to the cart, etc.) A simple visual of this relationship can be thought of
like this:

Input as a funnel
And yet, as a developer we know that there is some functionality we don’t see -
implicit in the code is the fact that the result of our calculate_shipping
function is not only affected by the data that is passed to it but is also
dependent on the behavior of TaxCalculator, calculate_shipping_price, and
get_customer_shipping_info . These classes and functions are immediate
dependencies in that our code calls them directly. Because of that, these are
also inputs to our function; while they are not passed into it directly, there
is code inside of them that is executed by the body of our function. If we
re-imagine our inputs using this information as well, we can see that it would
look more like this:
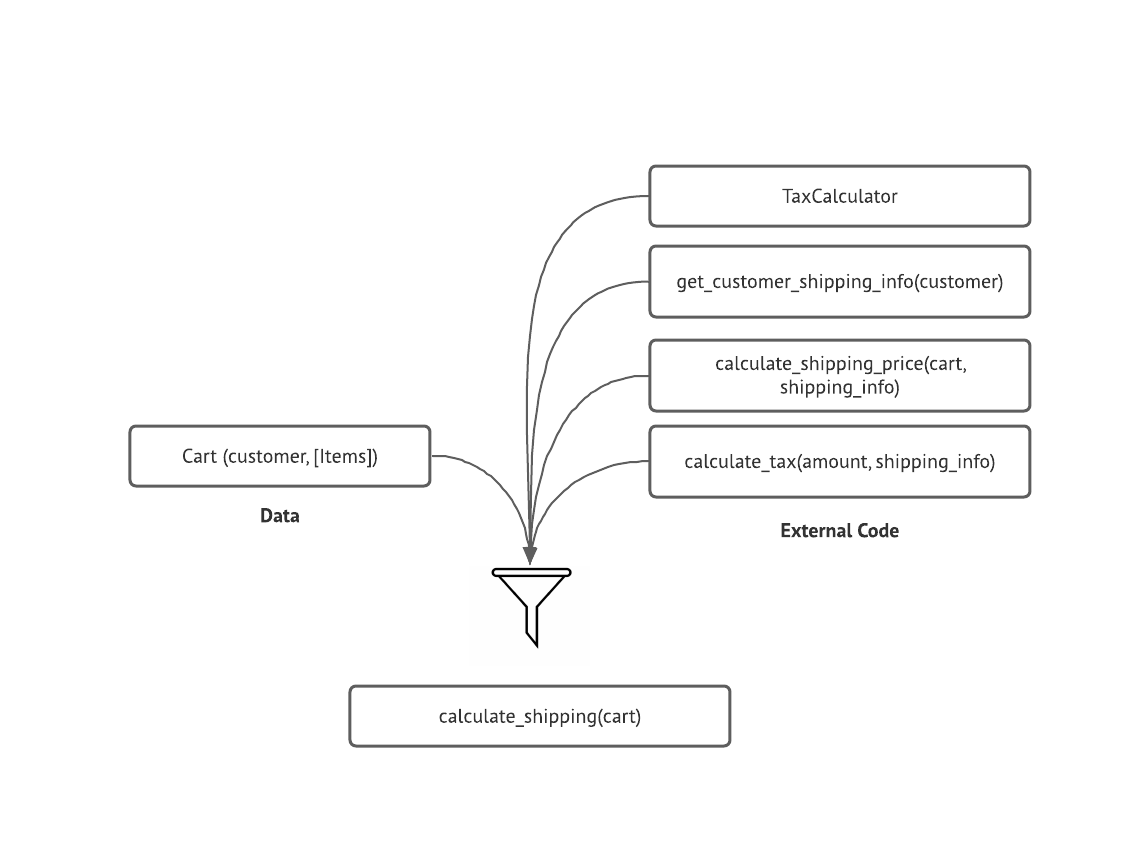
A slightly more complex input example
Here we can visualize that, not only is the cart itself an input, the function
calls inside our calculate_shipping function are also acting as inputs. Given
this, you may already be thinking about the next step in the system - the inputs
to those functions.
A side note: a function is said to be idempotent if the outcome of that function is unchanged given the same set of input(s). An underlying assumption about the YourBase acceleration technology is that tests being observed and accelerated are idempotent. That is, they are expected to be run independently and be side-effect free (they do not directly impact the execution of another test). One quick way to identify whether tests are idempotent is to run them in randomized fashion to reduce the chance of uncaught inter-dependencies (many testing frameworks do this by default).
Functions call other functions, call other…
As you can imagine, those functions probably call other functions and so on,
which creates a chain of dependencies. What may not be quite as obvious (without
prior knowledge or code traversal) is that this function also depends on
whatever code exists in (or is potentially called by) our cart and
shipping_info objects. These structures themselves in turn have their own
dependencies in the form of functions, classes, and structures that they rely on
as input. If anything in this incomprehensibly long chain of dependencies
changes its behavior, our output may change as well, making every one of them
transitive inputs into our function. (I mean, seriously, have you ever looked
at all of your dependencies? If not it could be a very eye-opening experience.)
Even with just a few external functions for each of our immediate dependencies, this begins to grow exponentially with each link in the chain. Take a look at the graph now if we only look at one more level of call-depth:
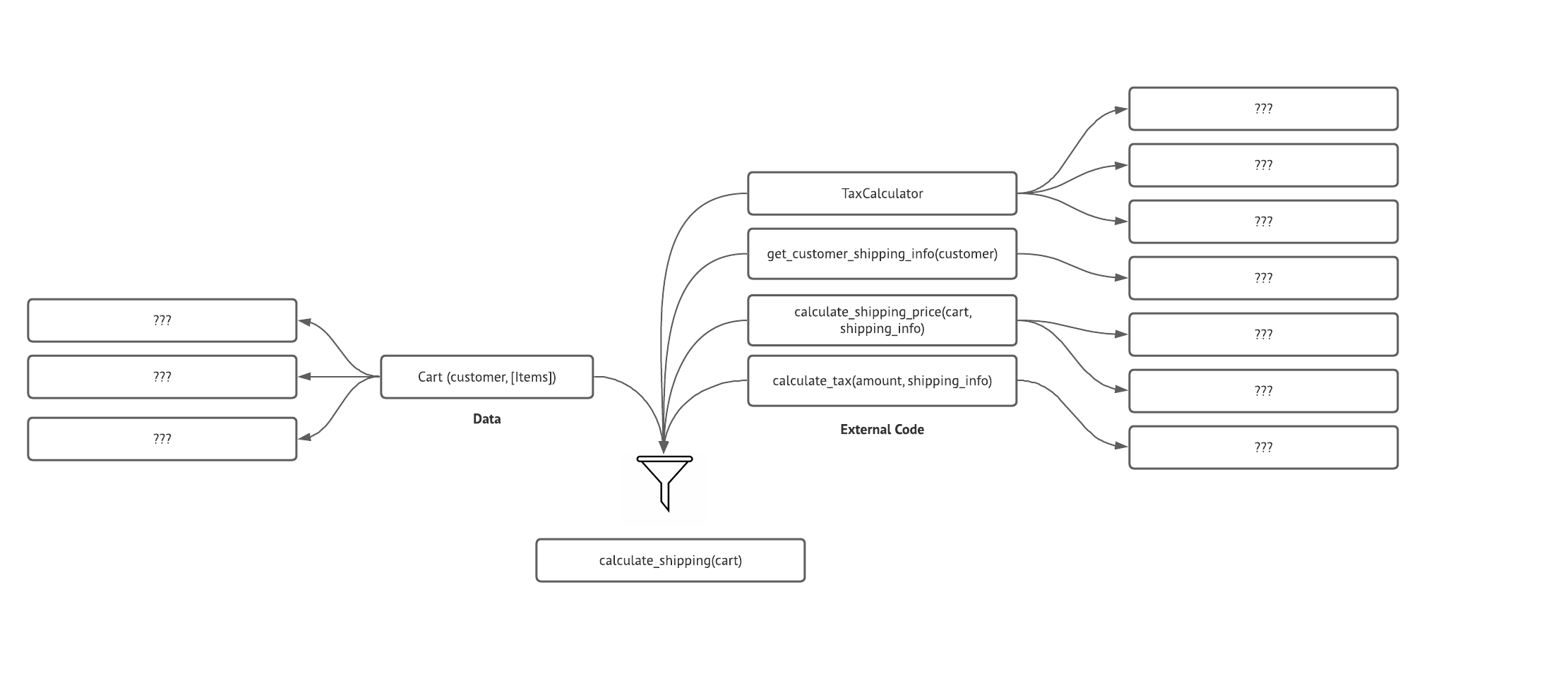
Exponential complexity
You can imagine that, if we take just a few steps away from the function we started looking at, trying to keep track of everything is a recipe for disaster (or at least a headache). We do this all the time without thinking about it; and I would argue that we shoudln’t need to think about it, at least not all the time. We need to be aware of this and how it affects our code and tests, not obsess over it.
My brain’s call stack just overflowed
As anyone who has spent much time programming can tell you, it’s nearly impossible to keep all of this in our brain. It’s just too much data to track in our head all the time so we rely on tools, best practices, and processes to help keep things working smoothly.
Some of this complexity is managed by the programming language or tooling itself: we have type-safe languages with compilers or interpreters that guarantee data takes the correct shape throughout the program; linters and style tools to help make code more readable and consistent so that humans can better understand it. All of these are great ways to help us build reliable, functioning, systems - but those are just guard rails. These, in some ways, actually amplify the problem by allowing us to lean on the computer to help make things seem simpler than they really are.
Best practices, such as keeping methods small, or building facades are designed to keep thing simple. If done properly, we should have smaller components that are more purpose-driven and easier to reason about. When we put these smaller components together we have a machine that is able to do what we ask of it. Much in the same way that a car is composed of mutliple subsystems – the engine, the steering, brakes, climate control, etc. these too help us to reduce the challenges of managing large systems.
In order to help prevent us from releasing broken software into the wild we need to test our software. Sometimes that is done manually, hopefully it’s done automatically, but, either way, we test its functionality before we say it works. In writing tests, we design them with the goal of proving to ourselves that portions of the system, and subsequently the system as a whole, function as expected. Tests take a lot of effort to write and maintain – in fact, sometimes the amount of code that we write for these tests eclipses the amount of code written for the program itself! Much of this is a result of needing to simulate the way that the software will be used in the wild, which can be unpredictable (even downright weird), so we need to simulate many different scenarios that might occur (or have occured) and break the system.
Due to the interactions between all of the components in any large system, our safeguards become an increasingly critical part of keeping complexity in check. Code reviews, CI systems, automated tests – all of these provide a different way to tackle the problem. Though effective, this has an impact on developers, their productivity and their confidence in the code they are writing. This, in turn, increases the cost of building new features for our business or customers.
Sorry I’m late for dinner, I had to wait for my tests to finish
We all know that tests require time to write and maintain, and that they need to be executed frequently in order to catch errors early in the process, both of which require developer time. We understand that the more frequently the tests are run, the higher our confidence in our work is; we rely on them to catch errors we would otherwise not be able to predict when we are writing code. These tests help ensure that the behavior of the system before the change remains the same after our work is complete.
If testing the software is painful, however, it can actually do more harm than good. When tests take too long, we are less likely to run them repeatedly during our development process (if at all). If tests are flaky or unreliable then they do not provide meaningful signal. Systems that have too many moving parts mean we are unable to run tests, even though we want to. All of these lead to technical debt in one form or another, which costs more to fix (in time and dollars) the further down the road you go.
In order to best catch, and fix, an issue before it is released, we should be able to run our tests during the process, in near real-time. If we can’t do this because they take too long, then tend to be run more infrequently; this is due to system resources being constrained, but also developer focus. Unfortunately, this is exactly where we want to be running them the most - when we are closest to the work being done and therefore best positioned to address any issues. If we can catch them while we are still working on the code, then we have all the context and focus required to fix things.
Tests need to be run on every build to be considered successful; but when tests fail intermittently or present other weird behavior they become noise instead of signals. If they become noisy enough then they will be silenced one way or another; it’s not uncommon for teams to comment out or delete tests that do not behave in a way they can explain or fix (which seems like the ones you really want to be fixing!) When systems are so hard to setup and configure that no developer can operate all the components required to test the system as a whole, then they often need to rely on shared environments or CI systems to do the builds for them. This can be slow for many reasons; shared environments may have capacity constraints, the CI system is slow or doesn’t always work, or other technical issues arise.
When this happens, and we run our tests less frequently, we have much lower confidence during the development process. We are unable to quickly tell that our code not only works correctly but that it is also side effect free, meaning that we haven’t inadvertently broken another part of the system as a byproduct of our change. If we are unable to determine this by running the tests quickly then we may end up pushing our fixes to the CI system in hopes that it succeeds while we move on to something else (or take really long coffee breaks) while the tests run.
Can we fix it? Yes we can!
I can personally attest to the pain of working on an incredibly large, unwieldy, code base. Along with this came with an unneccessarily high amount of pain when it came to adding new features or fixing bugs. Many times we would resort to all sorts of things: running our builds in the CI system very infrequently, running random subsets of tests that we thought were relevant to our changes, avoiding touching certain portions of the system because “they were scary”, and more.
Each and every time it seemed like we were hitting the same problem – an overly complex system with no way for us to begin to untangle it. Since we couldn’t untangle it we would try to solve it in other ways, none of them were ultimately very successful. A big part of what I’m working on these days is trying to address these problems from the ground up in order to reduce the pain of development.
Stay tuned!